




![]()
Dans la série de nos papiers sur les logiciels d’optimisation en chromatographie liquide, un article* très intéressant de l’équipe du Dr Molnár à paraître dans la revue LC-GC, nous permet de comparer deux des principaux logiciels disponibles : DryLab® et Fusion AE™ LC Method Development.
![]()
L’avènement des principes de « Quality by Design » (QbD) et la généralisation de la sous-traitance ont fait émerger de nouvelles problématiques dans le monde de la chromatographie. Elles peuvent se résumer en deux points : la prédiction de paramètres critiques (QbD) et la robustesse des méthodes d’analyse en vue de leurs transferts inter-laboratoires. Une des possibilités pour répondre à ces problématiques est d’utiliser des logiciels de modélisation. Il est donc utile d’identifier les deux familles de logiciels qui se partagent le marché.
On peut en effet distinguer d’une part les logiciels d’optimisation de méthodes et de modélisation qui s’appuient sur les lois théoriques chromatographiques (à titre d’exemple, on peut citer le logiciel DryLab®, développé par l’institut Molnár) et, d’autre part, des logiciels de plans d’expériences.
Il convient de s’arrêter un instant sur cette notion de plan d’expériences. On constate qu’il existe une confusion au sujet du terme « plan d’expériences » et encore plus dans le vocabulaire anglo-saxon avec le terme « Design of Experiment » (DoE). En effet, organiser un jeu d’essais dans le but d’étudier l’influence de paramètres sur une réponse est en soit une planification d’expériences mais pas un plan d’expériences. En effet, un plan d’expériences est avant tout une théorie mathématique qui permet d’optimiser la position des points expérimentaux dans le domaine d’étude : « La théorie des plans d’expériences assure les conditions pour lesquelles on obtient la meilleure précision possible avec le minimum d’essais »**. Il faut donc bien comprendre que derrière la notion de plan d’expériences se trouvent des modèles mathématiques théoriques qui permettent de mener à bien les calculs. En effet, la théorie des plans d’expériences propose une grande variété de plans qui s’appuient sur des modèles mathématiques sous-jacents différents et possèdent donc des propriétés différentes. On peut citer à titre d’exemples : les plans factoriel complets et fractionnaires, les plans de mélanges plans optimaux, les plans à facteurs mixtes, les plans pour surfaces de réponse (composites, Box-Behnken, Doehlert)… Cette science est en plein essor et de nouvelles théories continuent à être développées pour améliorer et obtenir des plans toujours plus efficaces.
Cette précision faite, nous pouvons retourner à notre sujet. Nous nous étions arrêtés à la seconde famille de logiciels, celle qui utilise les plans d’expériences (au sens mathématique). En chromatographie, ces logiciels sont assez rares. La plupart du temps ce sont des logiciels de calculs statistiques purs. Cependant, il en existe au moins un qui est dédié à la chromatographie (liquide) : Fusion AE™ LC Method Development, développé par S-matrix.
Dans tous les cas ces deux familles permettent de modéliser un phénomène chromatographique, d’établir des prédictions (fiables) de réponses étudiées (temps de rétention, nombre de pics, résolution…) et d’évaluer la robustesse d’une méthode d’analyse.
Cependant des différences importantes sont à noter et la principale est liée à la dépendance au niveau de connaissance que l’on peut avoir du problème chromatographique étudié. En effet, les logiciels comme DryLab® ont une efficacité qui dépend complètement de cette connaissance du phénomène et sont plutôt destinés à travailler sur un domaine d’étude préalablement défriché pour séparer des composés dont la plupart sont connus. En effet, le logiciel ne va pouvoir modéliser le comportement des composés d’un échantillon, via les lois chromatographiques, que si ces composés à étudier sont connus. Lorsque l’étude porte sur un domaine dans lequel peu d’informations sont disponibles (les produits de dégradation, par exemple) ce genre de logiciel commence à atteindre ses limites. Et c’est logique ! Ne connaissant pas les composés, il ne peut pas les modéliser…
A contrario, un logiciel de plans d’expériences (comme Fusion AE™) ne dépend absolument pas de la connaissance chromatographique du phénomène étudié. Il peut ainsi modéliser n’importe quel phénomène sans nécessiter de connaissance sur son sujet. Certes il ne pourra ni prévoir de chromatogramme ni identifier les pics mais il pourra prévoir toutes les autres grandeurs et proposer une solution optimale multicritère (résolution, nombre de pic, …) dont les prévisions se révèlent, à l’usage, extrêmement précises.
En ce qui concerne la robustesse, la question est plus délicate. Les méthodes d’évaluation diffèrent, ainsi que leurs mises en œuvre. Du côté de DryLab®, le module de robustesse est un logiciel en option. Son calcul se base sur une simulation d’essais autour du point de réglage : « Le module de robustesse génère jusqu’à 729 essais autour du point de réglage »***.
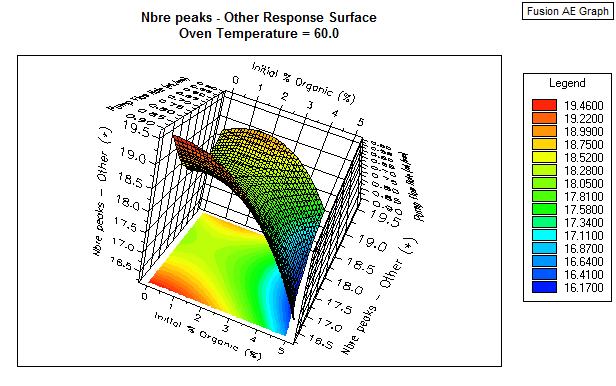 Le logiciel de S-matrix quant à lui utilise une simulation de Monte Carlo pour établir la robustesse. Il réalise 100 000 prédictions de réponses pour étudier la distribution des résultats ! Il fournit ensuite des valeurs de coefficients (capabilités) qui permettent d’évaluer la robustesse de toutes les réponses. Il est également possible d’intégrer la robustesse dans la recherche de l’optimum.
Le logiciel de S-matrix quant à lui utilise une simulation de Monte Carlo pour établir la robustesse. Il réalise 100 000 prédictions de réponses pour étudier la distribution des résultats ! Il fournit ensuite des valeurs de coefficients (capabilités) qui permettent d’évaluer la robustesse de toutes les réponses. Il est également possible d’intégrer la robustesse dans la recherche de l’optimum.
Concluons en remarquant tout de même que DryLab® est excellent dans son domaine et son interface graphique est très efficace, mais son domaine est également sa faiblesse. Sans connaissances approfondies sur le problème chromatographique étudié (nombres de pics, nature des composées, …) il perd en efficacité… Alors que Fusion AE™, malgré l’absence de prévisions de chromatogrammes, permet de prédire toute les réponses chromatographiques potentielles avec un degré de précision extrêmement élevé et ceci même avec des connaissances quasi-nulles sur le problème étudié. Il ne fournit pas le chromatogramme optimal mais les conditions pour l’obtenir.
Ces constations sont complètement liées aux méthodes de calculs et de modélisations qui répondent à deux philosophies très différentes. En somme, on pourrait comparer cela à un conflit de génération, voire à celui entre les Big Data et le raisonnement classique.
* : Quality by design in Pharmaceutical Analysis Using Computer Simulation with UHPLC by Robert Kormany, Imre Molnar, Jeno Fekete , Chromatography Online
** : Jacques Goupy, « Les plans d’expériences – Optimisation du choix des essais et de l’interprétation des résultats », édition DUNOD, 5ème édition.
*** : http://www.molnar-institut.com/HP/Software/Robustness_Module.php
Bonjour,
Merci pour votre article et pour le travail effectué sur ce blog. Pour ma part, je suis utilisateur de ces deux types de logiciels et je ne suis pas d’accord avec le fait qu’un logiciel de modélisation type Drylab ne va pas pouvoir modéliser le comportement des composés inconnus d’un échantillon. Le but du logiciel d’optimisation (Drylab) est de déterminer le comportement chromatographique de n’importe quel composé (et donc le gradient optimal à effectuer) sur la base d’un nombre d’expériences encore plus limité que dans le cas des plans d’expériences (Fusion), car un logiciel comme Drylab se base sur des modèles connus depuis bien longtemps en chromatographie.
Le vrai inconvénient de Drylab est qu’il nécessite de faire du « peak tracking ». Il faut donc identifier comment les pics se déplacent sur les chromatogrammes initiaux avant de pouvoir modéliser leur comportement chromatographique, ce qui peut parfois être long et fastidieux.
Avec Fusion, cette étape n’est pas utile puisqu’on va se contenter de compter le nombre de pics sur le chromatogramme (ou le nombre de pics séparés avec une résolution d’au moins 1.5) pour voir dans quelles conditions la meilleure séparation peut être obtenue.
Bonne continuation à vous,
Davy Guillarme
Merci Davy pour ce commentaire très intéressant.
Je pense que l’ambiguïté porte sur la terminologie employée (« composé inconnu ») dans mon papier. En effet, dans mon esprit la maîtrise du Peak Tracking dont vous parlez à très juste titre représente déjà une connaissance avancée du ou des composés à étudier.
En ce qui concerne le nombre d’essais, je n’ai pas de connaissance approfondie de DryLab mais j’ai repris les conditions expérimentales utilisées dans l’article pour programmer un plan d’expérience avec Fusion : avec un type d’expérimentation « RD2 – optimisation », j’obtiens entre 22 et 33 essais suivant le réglage (discret ou continu) de la température de four, sachant que le temps de gradient est une variable continue sous Fusion. Il est évident que la comparaison s’arrête ici puisque je n’ai pas pu éprouver un optimum fourni par Fusion, mais on peut tout de même constater un nombre d’essais inférieur aux 42 proposés par l’article.
Enfin, sauf erreur de ma part, la comparaison de colonnes avec DryLab reste à l’appréciation de l’utilisateur… contrairement à Fusion qui peut intégrer la variable « Type de colonne » à son plan et donc à l’optimum proposé.
J’espère que cette discussion va se poursuivre, et votre expérience de comparaison des deux logiciels m’intéresse beaucoup.
Paul Foulon
Bonjour,
Cette discussion nous intéresse particulièrement en tant que nouveaux utilisateurs à la fois de Fusion et Drylab. Les deux logiciels nous semblent pertinents dans le développement de méthodes chromatographiques. Du fait de leur fonctionnement totalement différent, ils ont tous deux des avantages et inconvénients.
L’utilisation de Fusion avec notre système UHPLC Waters nous permet de générer automatiquement une séquence sans créer de méthodes ce qui est un gain de temps conséquent. De plus, la comparaison de colonnes peut être faite directement dans Fusion. Drylab n’a pas d’interface d’acquisition des chromatogrammes et fonctionne en projet colonne par colonne.
L’utilisation de Fusion ne nécessite pas d’identifier les pics dans les différentes conditions. Avec Drylab, il s’agit de retrouver les pics d’un chromatogramme sur les autres chromatogrammes sans forcément les identifier. Pour cela, le logiciel utilise un système de reconnaissance (peak traking) par les surfaces de pic. Ainsi, que ce soit avec Fusion ou Drylab, on peut travailler avec un échantillon inconnu. Néanmoins, pour faciliter la compréhension chromatographique et éviter les erreurs, nous préférons réaliser des identifications de pics que ce soit avec Fusion ou Drylab.
L’utilisation de Drylab nécessite des connaissances importantes en chromatographie et on pourrait penser que ce n’est pas le cas de Fusion car le logiciel est basé sur des calculs mathématiques. Or, nous nous sommes aperçus qu’un chromatographiste « novice » pouvait passer à côté de conditions intéressantes en utilisant Fusion. En effet, concernant Fusion, il est préconisé de travailler à temps de gradient constant et de faire varier la composition finale et/ou la composition initiale du gradient. En effectuant cela, la pente de gradient change. Nous avons obtenu par exemple le plus grand nombre de pics avec une composition initiale Ci=5% en ACN et la meilleure résolution à Ci=10% en ACN. Or la pente de gradient a changé et le logiciel ne peut pas nous proposer de réaliser un gradient avec la même pente qu’en condition Ci=10% en commençant à 5% pour maximiser à la fois le nombre de pics et la résolution. En effet, dans ce plan d’étude, le temps de gradient n’étant pas une variable, on sort du cadre de l’étude. De ce fait, nous sommes obligés de refaire 4 plans d’expérience en optimisation en fixant la composition initiale ( par plan ) à 1%, 2% , 5 % et 10% et en faisant varier le temps de gradient en variable continue à 4min, 8 min et 12 min pour sélectionner la meilleure réponse . Dès le screening de colonnes, nous pensons que le temps de gradient devrait être une variable à étudier en laissant constante la composition initiale et finale sur la plus large gamme, quitte à devoir créer plusieurs méthodes d’intégration – ce qui n’est pas un problème en soi, puisque l’expérience montre qu’il est nécessaire de reprendre la majorité des chromatogrammes pour intégrer ce qui est réellement un pic produit. Ainsi il se pourrait que la colonne choisie dans ces conditions ne soit plus celle sur laquelle nous travaillons. Le temps nécessaire à ce plan serai gommé par l’automatisation sur un week end, puisqu’il n’ y a pas d’intervention manuelle.
L’inconvénient pour un chromatographiste en utilisant Fusion est de passer à côté d’un changement de sélectivité, puisqu’il n’y a pas de simulation de chromatogrammes. Le but de développer une méthode est de doser les composés, aussi il nous est toujours plus facile de doser une impureté à 0.1 % lorsqu‘elle est devant la substance principale. Fusion reste aveugle dans ce cas.
Avec Drylab, les chromatogrammes obtenus avec deux pentes de gradient permettent de visualiser les simulations pour d’autres pentes et/ou avec d’autres compositions. Ainsi, Drylab permet de tester virtuellement un grand nombre d’expérience et de réaliser l’injection de la solution la plus satisfaisante pour vérifier sa validité. Il a été montré (par exemple dans la publication Kormany et al. J. Pharm. Biomed. Anal. 89 (2014) 67-75) que les prédictions Drylab étaient très proches des chromatogrammes obtenus par expérience, ce qui est aussi le cas avec Fusion sur les réponses.
Amélie D’Attoma / Philippe Poisson – Technologie Servier
Merci pour ce commentaire très enrichissant.
Nous avons sollicité S-Matrix (développeur de Fusion AE) afin de comprendre leurs choix. La réponse a été très claire : il s’agit d’une contrainte mathématique.
En effet, Fusion AE modélise les phénomènes chromatographiques à partir de calculs de régression linéaire multiple. Le fait d’étudier Tg, Ci et/ou Cf simultanément ferait perdre de la précision au modèle.
En effet, avec la variation d’un paramètre (pente de gradient) dépendant lui-même de la variation d’autres paramètres (Ci, Cf et Tg), il n’est pas possible de déterminer la ou les variable(s) (Ci, Cf, ou Tg) qui a (ont) réellement eu un impact sur la réponse étudiée.
L’utilisateur serait lui-même embarrassé puisque la seule conclusion qu’il pourrait faire serait « la pente du gradient a une influence sur la réponse »… mais sans savoir si le temps de gradient est juste, si le %strong de départ est correct ou s’il faut modifier le %strong final.
C’est pourquoi le logiciel ne permet de travailler qu’avec une seule de ces 3 variables à la fois (Ci, Cf et Tg). De cette manière la modélisation ne perd pas en précision et on sait de quelle façon la pente a varié.
Paul Foulon
Hello Everyone:
« Fusion QbD » is the new registered trademark name for the Fusion AE Software. Fusion QbD now includes completely new chromatogram simulation and visualization technology. You can preview this on the S-Matrix website:
http://www.smatrix.com/fusion_lc_method_dev.html
You can also contact S-Matrix for a live web demo: sales@smatrix.com
Richard Verseput, S-Matrix